Se você está estudando inteligência artificial ou machine learning e quer entender a essência por trás disso, não apenas utilizar os algoritmos, mas realmente aprender como eles funcionam, mais cedo ou mais tarde você irá se deparar com o “temível” gradiente descendente.
Muitas literaturas comentam sobre esse algoritmo, mas é difícil encontrar um lugar que explique exatamente o que ele é e como ele funciona. Este é, então, o objetivo deste artigo: explicar melhor o que é gradiente descendente.
Pode parecer muito complexo, mas o conceito de gradiente descendente na verdade é simples de ser compreendido. Além disso, vários algoritmos de machine learning utilizam esse método, especialmente as redes neurais.
Ou seja, compreender bem essa ideia servirá como um fundamento muito sólido tanto para a compreensão de conceitos mais avançados posteriormente quanto para a construção de seu conhecimento.

Aqui daremos um panorama do assunto. Explicaremos um pouco a matemática envolvida, mas o foco será em exemplos simplificados que facilitam o aprendizado.
Otimizando o caminho
Antes de começar com exemplos específicos, vamos analisar a seguinte situação: imagine que você está viajando de carro de São Paulo à Porto Alegre para conhecer a casa de um amigo o qual nunca visitou.
Quando você sai de São Paulo, você pega rodovias federais e anda com uma velocidade alta; quando você entra em Porto Alegre, sua velocidade terá que diminuir, pois não podemos dirigir dentro de uma cidade com a mesma velocidade de uma rodovia.
Ademais, como você nunca esteve na casa de seu amigo, à medida que você se aproxima do endereço, é muito provável que sua velocidade diminua mais ainda, porque você não quer ir além do local desejado, o que faria você gastar mais gasolina e perder tempo. Quando você encontra a casa, você para o carro e finalmente pode descansar de sua longa viagem.
Agora você pode estar se perguntando: o que tudo isso tem a ver com gradiente descendente e regressão linear? Ora, o exemplo pode parecer estranho, mas ele ilustra bem como esses algoritmos funcionam.

Quando utilizamos a regressão linear, nós estamos tentando escrever uma reta (uma função) que melhor se adeque a uma relação de dados, ou seja, estamos tentando encontrar um caminho que nos leve ao destino da melhor maneira possível.
O gradiente descendente, por sua vez, é a maneira de otimizar esse caminho para que você encontre o destino de forma efetiva e sem gastos desnecessários.
Ele começa em um determinado valor da função (São Paulo, em nosso exemplo) e “anda” em direção ao mínimo (a casa de seu amigo em Porto Alegre).
Quando está longe desse mínimo, o algoritmo anda mais rápido; à medida que vai se aproximando do valor desejado, ele diminui a velocidade até que finalmente para ao chegar no destino.
Aplicando o gradiente descendente na regressão linear
Entendendo melhor o que é o gradiente descendente, podemos aplicá-lo na regressão linear. Como dito anteriormente, quando utilizamos a regressão linear, nós estamos tentando construir uma reta que melhor explique uma relação de dados. Analise o gráfico abaixo:
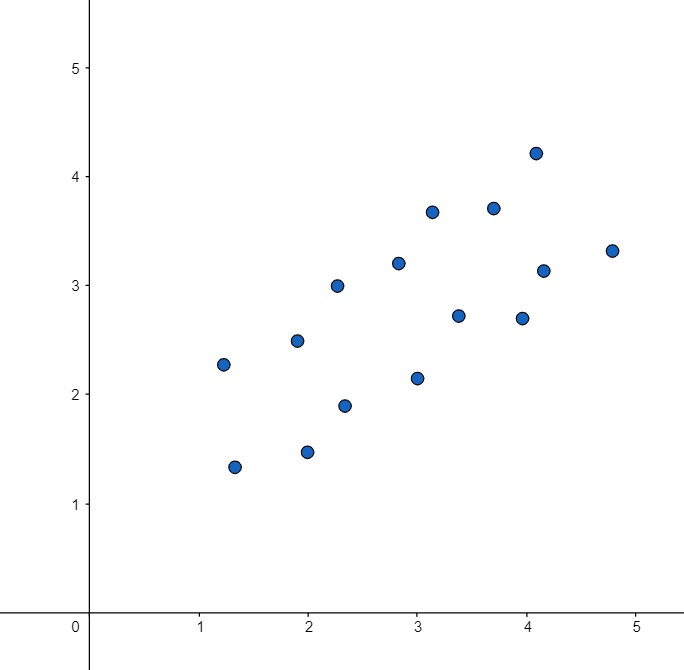
Neste gráfico, temos vários pontos de dados (x em respectivos valores de y). Com a regressão linear, o que queremos é uma função que descreva o comportamento desses dados.
Nós, na verdade, estamos procurando uma reta que explique bem o comportamento dos nossos dados: a reta mais ajustada possível, que melhor mostre a relação do X com o Y.
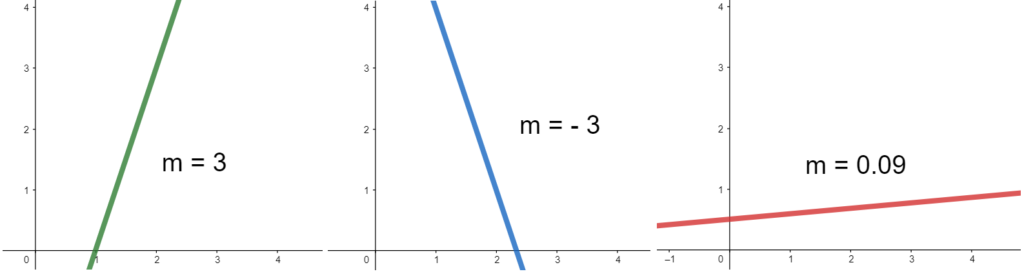
Esta reta será uma função, então podemos representá-la com a equação “y = mx + b“. Ela tem um valor de m (o coeficiente angular) que é constante e determina o quão inclinada a reta será. Um m positivo muito grande representa uma reta muito inclinada “para cima”; um m negativo representa uma reta inclinada para “baixo”; um m muito próximo de zero, por sua vez, representa uma reta que forma um ângulo pequeno com o eixo X.
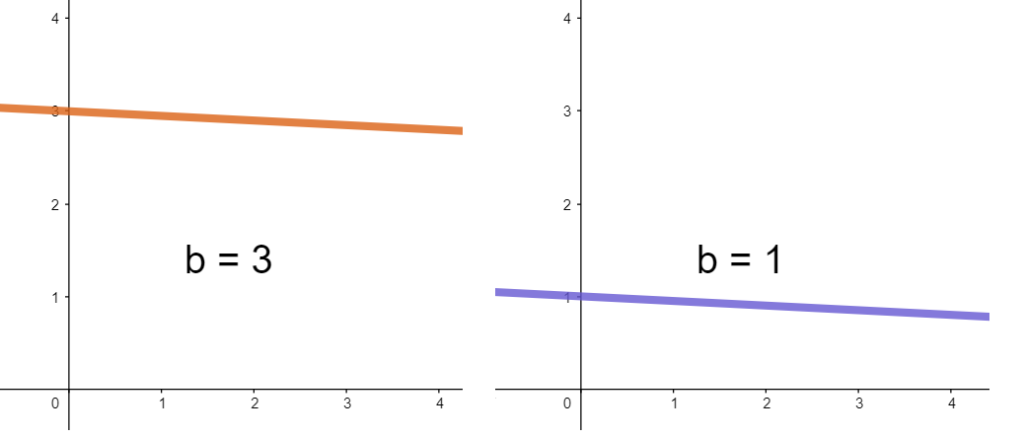
Além da do coeficiente angular, nós também temos o coeficiente linear (representado pela letra b) que nos diz o quão deslocada está a função: o coeficiente linear é o ponto em que a reta corta o eixo y; um valor de b muito alto coloca a reta para cima; um valor de b muito baixo coloca a reta pra baixo.
Para qualquer valor de b ou de m teremos todas as retas possíveis de serem desenhadas nesse plano XY. Cada uma dessas retas terá uma equação com valores específicos de m e de b. O queremos é o seguinte: encontrar os valores de m e de b que desenhem a reta mais aproximada possível dos dados.
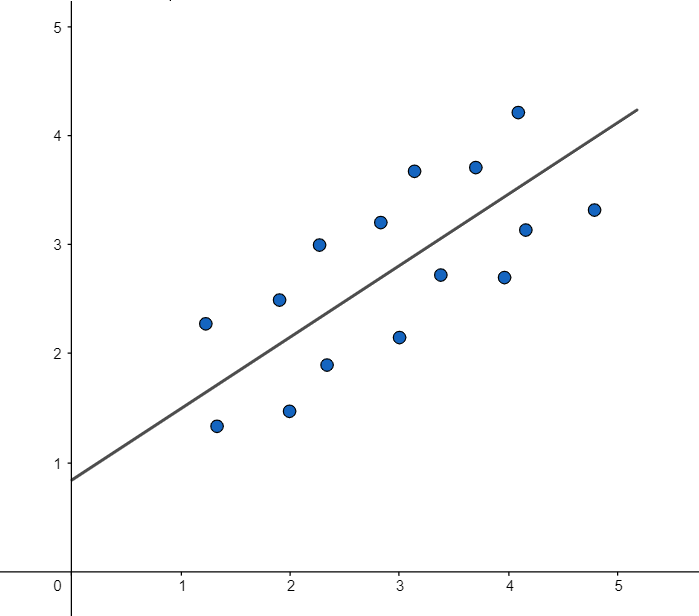
Como nosso algoritmo poderia encontrar a equação dessa reta? Existem algumas estratégias. Já que nosso computador faz as coisas rapidamente, nós poderíamos fazer com que ele selecionasse alguns valores aleatórios de m e de b para construir várias retas.
Em uma reta, m valeria 5 e b valeria -20; em outra reta, m seria 17,2 e b seria -79, e assim por diante. Existem praticamente infinitos valores e combinações de m e de b, e cada um desses pares de valores construiria uma reta diferente.
Seria possível solicitar que nosso computador construísse 1 milhão de retas diferentes (1 milhão de combinações de m e b). Depois de construir essas retas, nós analisaríamos qual seria a reta mais adequada a todos os dados; a reta que melhor se encaixasse seria a decisão final desse algoritmo.
Essa estratégia até funcionaria; mas não seria muito inteligente: afinal haveria um grande dispêndio computacional e o resultado final pode não ficar o melhor possível. Nós estaríamos dependendo da sorte. Podemos fazer melhor do que isso.
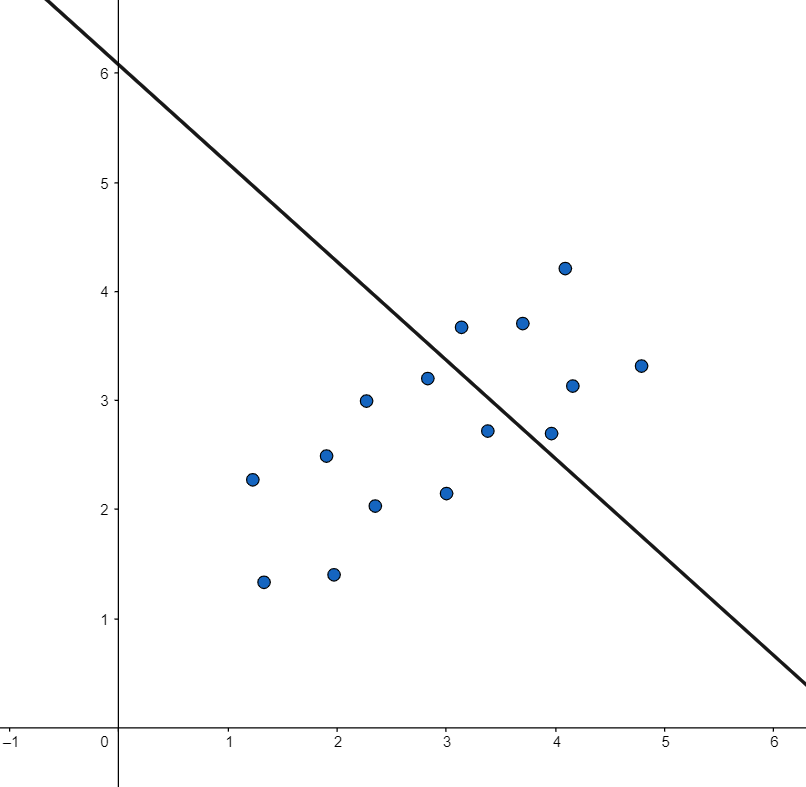
Vamos pensar no seguinte: ainda não temos noção de quais são os valores de m e b que se encaixam em nossos dados. Podemos começar com valores aleatórios; mas na próxima tentativa, em vez de simplesmente “chutar” novos valores de m e b, podemos utilizar outra estratégia.
Por que não variar um pouco o valor de m? Digamos, se começamos com m = 60, na próxima iteração podemos diminuir para 59, por exemplo.
Assim, nós comparamos as duas retas observando o erro (a distância dos valores reais para a reta). Se essa nova reta se adequa melhor ao conjunto de dados, possuindo um erro menor que a anterior, isso é um sinal de que caminhamos na direção correta e podemos continuar variando o m nessa direção.
Após isso, procederemos da mesma forma com o valor de b. A cada nova iteração, estaremos um passo à frente na direção certa, na direção do resultado desejado. Obviamente, se após essas tentativas as retas forem menos adequadas, nós devemos caminhar na direção oposta.
É possível, entretanto, que o valor inicial esteja muito longe do ideal; é possível que a reta que escolhemos esteja completamente fora do comportamento dos dados.
Em uma situação como essa, se caminhássemos de pouco em pouco em direção ao resultado certo, levaríamos muito tempo para atingir nosso objetivo. Nesse caso, o melhor seria fazer variações maiores – não apenas uma unidade: se o valor inicial de m fosse 60, poderíamos mudá-lo para 15, por exemplo.
Assim, à medida que formos nos aproximando do resultado ideal – quando teríamos um erro menor – começaríamos a fazer alterações de unidades menores.
Em outras palavras, quando estamos muito longe do resultado, caminhamos a passos largos; quando nos aproximamos do resultado, começamos a dar passos mais curtos. Dessa forma, chegamos mais precisamente no ponto ideal – de maneira análoga ao nosso exemplo da viagem entre São Paulo e Porto Alegre.
Essa, então, é a melhor estratégia até agora; é a forma mais otimizada de começarmos em um valor aleatório e caminharmos na direção certa em uma velocidade certa.
Tais exemplos são, na verdade, o conceito de gradiente descendente: um algoritmo inteligente que começa em um valor e, a partir dele, tenta calibrar as variáveis – m e b, no caso da regressão linear – de tal forma que, quando estamos muito distantes do valor ideal, caminhamos rapidamente.
Da mesma forma, quando estamos mais próximos do valor desejado, caminhamos mais lentamente.
Para uma explicação completa, com detalhes matemáticos, confira o vídeo abaixo:
Continue estudando
Esse tópico tocou em questões relacionadas à matemática. Por isso, para que você aprofunde seu conhecimento, sugerimos que assista as seguintes aulas:
Se você gostaria de aprender matemática ao mesmo tempo em que aprende machine learning e programação, para se tornar um bom profissional que sabe resolver problemas da vida real, comece por nosso curso de machine learning com Python.
Leia também:
- Gradiente Descendente Estocástico
- Aprendizado Supervisionado e Não Supervisionado
- Problemas de Classificação e Regressão
- Dados de Treino e Teste
- Underfitting e Overfitting
- Percentil e quartil
- Conceitos de Variância e Viés
- Entenda o básico de probabilidade
- De onde vem o número de Euler
- Regressão linear com linguagem R
- Redes Neurais e Deep Learning
- Redes Neurais em Problemas de Regressão